Query Optimization
This lesson describes the query execution process and presents the most frequently used techniques to optimize query performance.
Query Under the Covers
Sometimes the response time of a SQL query is not as fast as you expect or need. This kind of problem is more frequent with analytic query workloads than with transactional workloads. No matter the workload you are using, there are techniques you can apply to improve the query performance or response time. This tutorial covers several different topics to help you improve the performance and to understand the mechanics of executing a query.
The first point is understanding what affects query performance. SQL is a declarative language: when you write a query, you indicate the data you want to obtain as a result, but not necessarily anything about how the data is obtained. The responsibility for obtaining the data is the job for the database software, more precisely an internal module called the planner or optimizer.
The planner has one simple task: find the best (or fastest) way to execute a query. In database jargon, this is the best execution plan. The planner uses two basic sources of information:
- Database Schema: the tables, columns, indexes, and views in the database.
- Database Statistics: metrics such as quantity or records in a table and quantity of unique values, and other statistics are usually stored in the database catalog.
Query time is composed of the planner time plus the execution time. The planner time is typically very short. The execution time is the part to optimize. Different execution plans have different query execution times.
In some cases, the best execution plan chosen by the planner is not the optimal plan, resulting in slow response time. In this case, try these techniques to improve the query performance.
Analytical Queries versus Transactional Queries
Queries are different in analytical versus transactional databases. Typically:
- Transactional systems read and process only a few records to obtain a result. Indexes are used to optimize queries.
- Analytical systems read and process thousands of records, using GROUP BY clauses or aggregate functions. Indexes are not very useful. Techniques including partitioning or data pre-calculation of data (cubes) are used to improve performance.
Show Me the Best Execution Plan
You cannot define how the query is executed, however you can ask the planner to show the best execution plan chosen. There is a non-standard SQL statement, usually called EXPLAIN, that shows you how a query is executed. This example uses EXPLAIN in a PostgreSQL database.
The population table has 20 million rows, and no indexes. Here is the query:
SELECT ssn, last_name, first_name
FROM population
WHERE zip_code = ‘City136’
Here is the result of the EXPLAIN:

The database performs a Sequential Scan on the table population, and then applies the filter zip_code = ‘City136’ for each row.
The execution of this query takes about 43 seconds, which is not a good response time. A first conclusion for query performance: Try to avoid the combination of big tables (millions of rows) and sequential scans.
Performance Tips
These tips are not applicable to all queries, nor do they always improve performance.They are all part of your toolbox to use and try when you write a query.
- Avoid DISTINCT
- Optimize your SELECT
- Use Wildcards with the LIKE Operator on Indexed Field
- Maintain your Database Statistics
Avoid DISTINCT
The DISTINCT clause discards duplicated rows from the query results, qualifying complete rows (not columns). When a query has a DISTINCT clause the database executes an extra sort after obtaining the result set to discard the duplicated rows. If you know your query result set does not include duplicate rows, avoid using DISTINCT.
Here is a query using DISTINCT. The response time is 1 minute 30 seconds (lower right corner):
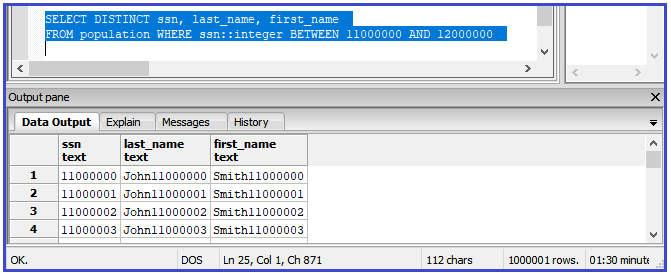
Here is the same query without DISTINCT. It takes only 55.6 seconds!
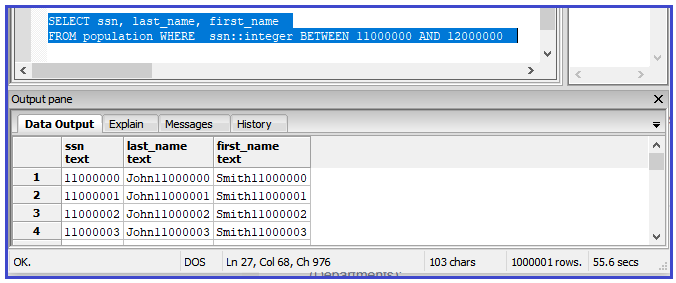
Optimize your SELECT
This tip applies to tables with many columns. In a 4 column table, selecting 2 columns is not going to show a lot of improvement. In tables with 20+ columns, especially if there are long lengths (CHAR(200) for example) it is optimal to SELECT the specific columns you need, instead of using SELECT *. You reduce both the volume of bytes the database has to process, and the volume of the data being sent between the database and the application.
This query uses the SELECT * statement to find ssn values between 11000000 and 12000000. The execution time is 1 minute and 2 seconds.
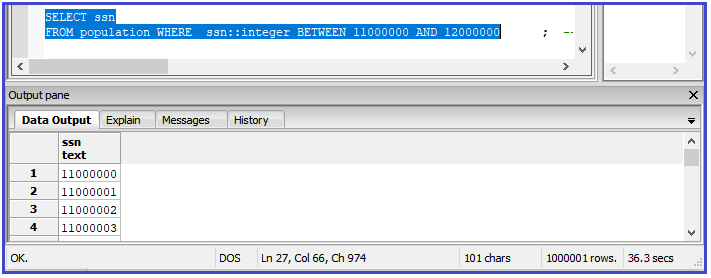
This query optimizes the SELECT statement to find ssn values between 11000000 and 12000000. The execution time is 36.3 seconds!
Use Wildcards with the LIKE Operator on Indexed Field
This tip applies specifically to situations where you have an indexed field where you can use the LIKE operator in your query. Using the wildcard at the end of the phrase speeds up the query performance. This is something to keep in mind when designing your data set.
This example uses a table named population where the key is last_name.
This query takes advantage of the index using a wildcard at the end of the search string:
SELECT ssn, last_name
FROM population
WHERE last_name LIKE ‘Smith1%’
This query with the wildcard at the start of the search string cannot take advantage of the index, resulting in a sequential scan on the entire table:
SELECT ssn, last_name
FROM population
WHERE last_name LIKE ‘%mith1000000’
Maintain your Database Statistics
The database statistics are used by the planner to calculate the best execution plan for each query.
Your database administrator defines how and when your database statistics are refreshed. If your statistics are out of date, the planner creates execution plans based on faulty information. For example, if the statistics show the table population has 100 rows, the planner might choose a sequential scan as a low cost operation. If the table actually contains 2000000 rows, the sequential scan is a bad execution plan resulting in a slow query.
Closing Words
In this lesson you learned about the internal workings on query execution and a few techniques to try to optimize your queries. Keep going, learn SQL and increase your skills!


